India’s push to build multilingual artificial intelligence is being framed as a matter of inclusion, but a growing debate is asking a more fundamental question: who controls the language data that makes these systems possible? A recent Observer Research Foundation essay argues that AI remains overwhelmingly English-led, even though English is spoken by a minority of the world’s population, and warns that low-resource languages are far more costly to source and process. In India, where most people are not native English speakers, that imbalance has turned language stewardship into a governance issue rather than a purely technical one.
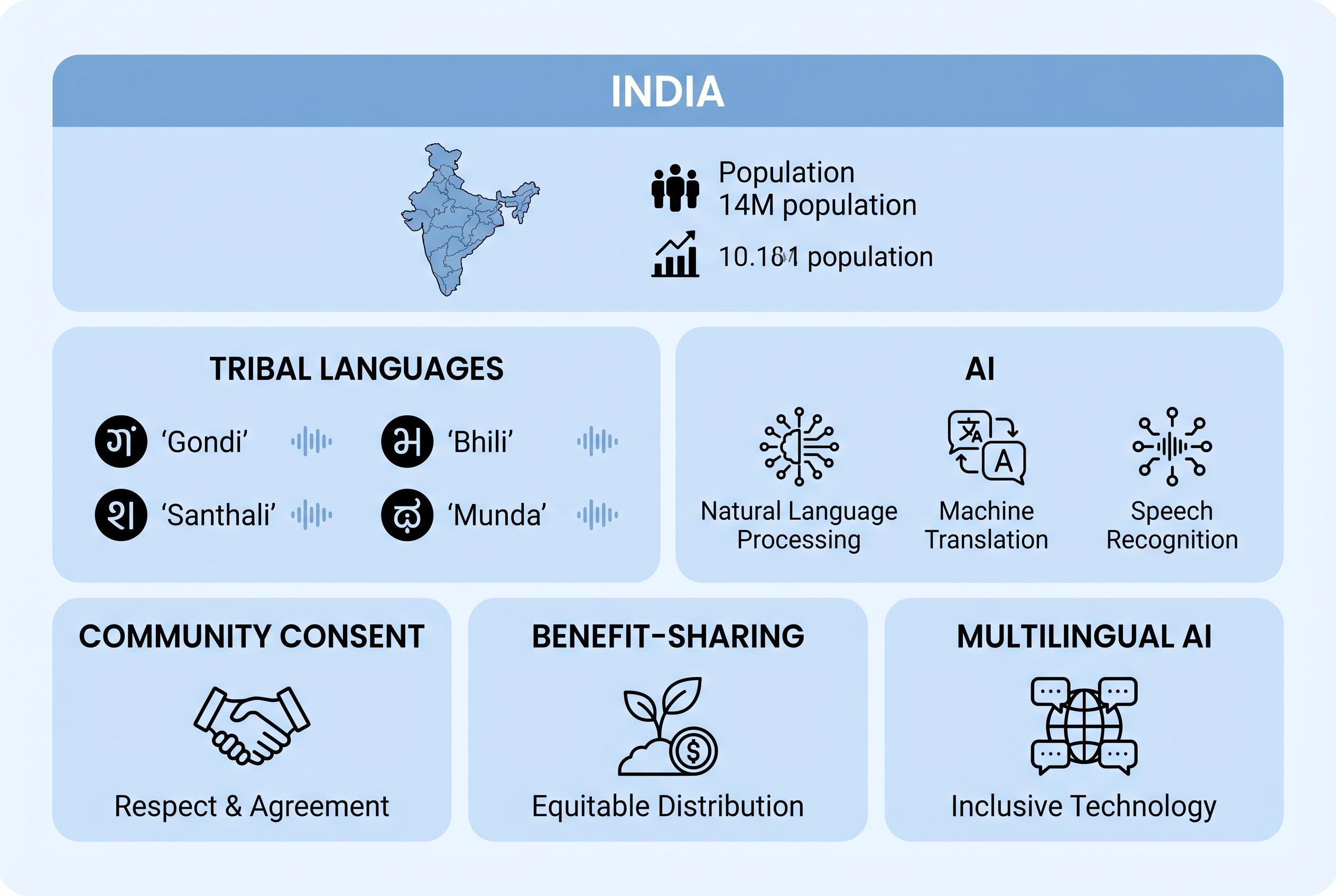
The scale of India’s ambition is unusually large. Government material on BHASHINI says the platform is designed to support the 22 scheduled languages and several tribal languages through translation, speech-to-text and voice tools. The same multilingual push includes BharatGen, a government-backed large language model, and Adi Vaani, introduced in 2025 to support tribal languages such as Santali, Bhili, Mundari and Gondi. Business Standard reported in February that BharatGen is preparing a 17-billion-parameter multilingual model, Param2, for release at the India AI Impact Summit 2026, underlining how quickly the state-backed ecosystem is moving from pilot programmes to national infrastructure.
But the ORF essay says the central problem is not coverage alone. It argues that language archives gathered for preservation purposes may now be feeding AI systems without communities being properly told, consulted or granted any continuing say over how their speech is represented. That concern is especially acute for tribal and oral languages, where a small corpus or a single dialect can become disproportionately influential once embedded in a model. The essay says current disclosures around BharatGen and Bhashini do not fully answer questions about community consent, representation or benefit-sharing.
Existing Indian law, the piece adds, is ill-suited to this challenge. Privacy regulation is built around individuals, yet linguistic corpora are collective by nature. A set of folk songs, agricultural terms or oral histories may not identify a single person, but misuse of that material can still affect an entire community. The author argues that India’s AI governance principles, announced in 2025, are not enough on their own because they do not create a clear legal route for communities to object to, shape or negotiate the use of their language data.
To fill that gap, the essay points to other models. It cites the Traditional Knowledge Digital Library as an example of how India has previously documented shared knowledge to deter unauthorised commercial use. It also looks to Canada’s FirstVoices platform, where Indigenous nations retain ownership and control over language material, and to New Zealand’s Kaitiakitanga licence, which treats stewardship as a form of guardianship rather than a purely open-data problem. The common thread, according to the author, is that language should be treated as a community asset, not simply as raw material for model training.
The policy proposals are specific. MeitY is urged to require data declaration records for any model funded under the IndiaAI Mission, setting out which languages are included, which dialects are missing and what consultation took place. The essay also proposes language data trusts for low-resource languages such as Santali, Gondi, Bodo, Maithili and Mizo, with elected community representation at their core. In parallel, it calls for community-verified language data commons that could host corpora with provenance records and licensing terms that include benefit-sharing and representation checks. The broader argument is that India’s multilingual AI strategy will be judged not only by how many languages it can process, but by whether the people who speak those languages have real authority over how they are encoded.
Source Reference Map
Inspired by headline at: [1]
Sources by paragraph:
- Paragraph 1: [2]
- Paragraph 2: [3], [4]
- Paragraph 3: [1]
- Paragraph 4: [1]
- Paragraph 5: [1]
- Paragraph 6: [1], [5], [7]
Source: Noah Wire Services